The Illusion of Trust: The Declining Credibility of...Everything
tldr
In the digital age, data and content have not necessarily made us smarter. Despite democratized information produced at a breathtaking pace, the reality is far that the channels we depend on - Google, thought leaders, the media, and social media - are surprisingly untrustworthy. And yes, parts of the article are probably wrong since they were based on the same sources. Beyond the terrifying fact that fact credibility is in short supply and that sucks, this also has real ramifications for readers, creators and marketers. But first, let’s take a step back.I. Before We Knew Everything
What do you actually know?
I’m talking information that you know with a know it in your bones, apple-is-red degree of certainty. Today, if there was something you weren’t sure about, you’d Google it, ask AI, or ask someone who you think knows.
But on-demand information is shockingly new. In the ‘90s, if a friend at a bar claimed Jimi Hendrix produced the Muppets, people would argue, shrug, and then move on. Uncertainty was one of the defining characteristics of the Nineties, according to Chuck Klosterman.

Jimi Hendrix's Muppets, of course
A surprisingly little amount of knowledge was actually captured and made available. In the 90’s, if you missed a Seinfeld episode and it’s rerun…you just didn’t see it again. As a matter of fact, huge swaths of television between the 70s and the 90s are only available because a woman named Marion Stokes recorded them herself on 71,000 VHS cassettes. Talk about a hobby.
Trustworthy sources did exist in the shape of books and peer-reviewed journals. And before that, it was simpler. The fathers of modern science discovered their own facts. If they got a fancy letter with a wax seal container breaking science, they would try it themselves. It was easier since the surface area of knowledge was smaller, more discoverable and less dependent on specialization.
I’m getting to the point here.
Today, we have information at our fingertips in seconds. But can we trust it?II. The Illusion of Trustworthy Information
No, we can’t. While _most _of what we find of it is right, a lot is not.
- Google’s top results aren’t there because they are right (usually)
- Reporters are hit hard with aggressive quotas, floundering business models, and an overreliance on “experts” that are there to game the system
- AI depends on that same flawed and gamed information that Google or the media depend on (assuming it’s processors aren’t tripping shrooms and hallucinating fictional court cases)
- Marketers (cough) are twisting their data to push products and garnering global attention.
It’s bad. Potentially worse than you think. Let’s take a look at how it’s all gone off tracks. And then, when you know that you shouldn’t trust me at all, I’ll walk through what this means.
III. Borrowed Trust in Media: the Tip of the Iceberg
A caveat here. I know that it’s cool to bash the media but, as I said, this is still one of our best bastions of truth. But parts are still terrible for trust.
Here’s an example.
A friend of mine who invests in mobility recently remarked that he always thought that the New Yorker was top of the line reporting. Until he read an article covering electronic cars - his specific area of expertise. He found the article shallow and wildly inaccurate. And then he was left wondering... what else that he's read is off.
I’ve been on the other side of this equation, sounding off in articles as a Quoted But Absolutely Not Subject Matter Expert (QBANSME, if you will).
Data marketing is a core part of my marketing approach and when you provide data to reporters, you also get asked for comments. I’ve been in the New York Times talking inflation, in the Financial Times talking air and sea freight combinations, and in the Washington Post talking small business e-commerce behavior.
I (probably) shouldn’t have been.
In every one of those cases, there were experts who know these topics far better than I do. There may be turtles in the Bronx Zoo who do too. But the reader doesn’t always know that. They just assume reporter did due diligence when choosing the source.
And sometimes they just can’t.
Set aside the Jayson Blairs or Stephen Glasses who make up facts.
The truth is less heinous.
Reporters are pushed to produce more, increasingly pushed to selectively cover based on agendas, boots-on-the-ground reporters are losing their jobs, and ad revenue is compromising coverage. The industry itself is under fire, with layoffs left and right due to the loss of its historically core revenue stream - advertising.
As Jay Rosen puts it:
The ad industry doesn’t need the news industry when there are so many other ways to purchase attention, and so many better ways to target users.
This triggered Buzzfeed and Vice getting shut down, and layoffs at Fortune, Time, Business Insider, CNN, NPR, and more So it became a numbers game. More articles = more eyeballs = more ad revenue. A reporter at The Messenger, a venture-backed newspaper tweeted after eight months in which he published 630(!) articles:
This company worked its news and audience reporters to the bone over the last eight months. I wrote 630+ stories in that time, most of them were just copying and pasting work that other reporters put time and effort into, just for us to swoop in and, essentially, steal it…
That’s two hours per article, assuming no lunch break.
The drive to churn out information and a focus on output rather than input means that accuracy almost by definition becomes a victim.Downsizing made this even worse with positions like investigative reporters and local news reporters getting fired. As a result, 200 US counties don’t have a local newspaper and only half have one. Without bottom up news, the facts simply don’t surface as much.
Beyond fewer people and more required output. the drive for revenue also creates misaligned goals. This Atlantic article about the KitchenAid mixer starts with the beefy line that “Modern appliances are rarely built to last. They could learn something from the KitchenAid stand mixer.” Then it then takes a hard right turn towards irony with an inline ad for an affiliate-revenue generating link “Read: Too many Americans are missing out on the best kitchen gadget.”
This from a paper whose mission is:
Since 1857, The Atlantic has been challenging assumptions and pursuing truth.
Pursuing truth…and garlic peelers.
Media polarization leaves a mark. For example, James Bennet, the former New York Times Editorial Page editor wrote a scathing article in The Economist about the agenda that the paper pushed, resulting in selective and non-comprehensive coverage. I don’t know whether this is new or not but it’s certainly gotten worse as the world has gotten more polarized.
Ghosts of Media Past
The ghosts of decreased media organizations are even more harmful though.
Take the incredible story of the Clayton County Register. Once the official publication of a 343 person city in Iowa, the website of the paper was acquired and quickly became an orgy of AI-generated articles about stocks and pharmaceutical AI companies, all of which looks legit…and is actually published on the website of an official newspaper.
One of the fake authors, writing under the pen name of a former XFL player, published 14,882 articles , including over 50 in one day. But the authors forgot to remove some telling signs like:
“It’s important to note that this information was auto-generated byAutomated Insights.”
The full read on this is fascinating but it is just another nail in the coffin that ensures that seeing something in the media doesn’t mean what we sometimes think it means.
By the way, just to make this even more confusing, even though this was the subject of a massive expose, the official Clayton County website still has the Register listed as an official source.
The Caveat
I want to throw a few important caveats on this:
- Media accuracy was likely never bulletproof. British reporting of the battle of the Somme, one of the hardest fought battles that saw some 100,000 British soldiers killed, 20% of whom were killed on the first day, reported “our casualties not heavy.” Reporters are people too and the fog of war is real. But it exists in all domains.
- Reporting is profoundly difficult. With so much information produced, it’s near-impossible to buck the trend. One saving grace may be going deeper instead of broad. The Atlantic just started to turn a profit, with two thirds of their revenue coming from subscriptions by leaning aware from breaking news and more into in-depth coverage.

Newspaper from the Battle of the Somme
Source: The Conversation
IV. Data Gone Bad
The raw data being generated, consumed, used in articles or posted online is meh at best. This is for a range of reasons, from underlying flawed data to less-than-trustworthy data to an influx in marketing-produced data:
Misinterpreted Data, Flawed at the Source
Let’s start with bad data. Check out this whopper of an example from Noah Smith, in an often-cited statistic that US maternal mortality in the US is higher.
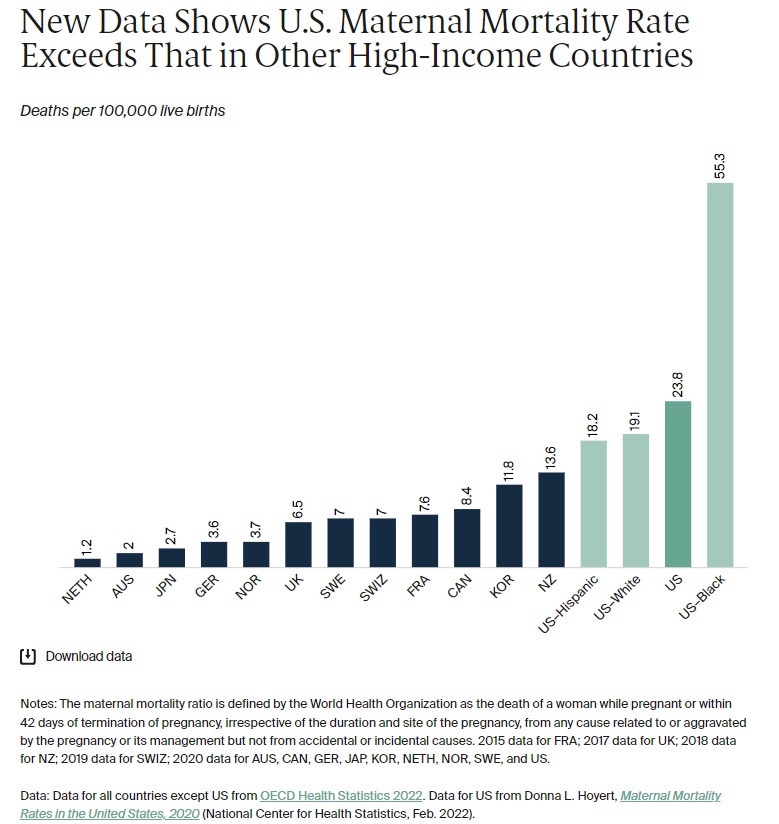
Graph that is very, very wrong
Panic, right?
Well, no. The spike everyone was reporting on was because of - drumroll - a new checkbox. Smith explains:
Only there’s one slight problem:_ The recent increase may not have happened at all_. Starting in 2003, U.S. states started rolling out a change to death certificates — a checkbox for pregnancy at the time of death. This resulted in a whole lot more deaths getting labeled as pregnancy-related.
The underlying data was wrong and even world-class experts didn’t pay attention to it. And this is just one that someone spotted.
Correctly Interpreted But Still Wrong Data
A scary number of peer-reviewed and published research reports are just plain wrong or, at the very least, not replicable. As Vox summarizes when presenting the Replication Crisis:
One 2015 attempt to reproduce 100 psychology studies was able to replicate only 39 of them. A big international effort in 2018 to reproduce prominent studies found that 14 of the 28 replicated, and an **attempt to replicate studies from top journals Nature and Science** found that 13 of the 21 results looked at could be reproduced.
These research reports are compiled by real human beings who aren’t above nudging numbers in the right direction, even if unintentionally. For example, Jordan Ellenberg, a mathematician pointed out that in published scientific research articles, scientests are not above nudging data around:
In fields ranging from political science to economics to psychology to sociology, statistical detectives have found a noticeable upward slope as the p-value approaches the .05 threshold.
In other words, if a researcher runs a test and finds that it is just under statistical significance, it encourages him or her to reanalyze data while removing some data points, probably while coming up with what sounds like a decent excuse (“well, what happens if we exclude men with excessive facial hair from the research cohort”).
So even when we do hear a podcast citing research in JAMA or read a book with a compelling chart…cited =does not mean verified.
The Marketers are Coming, Zillow, Cameo
And there’s a whole other category of data that can’t be trusted. And it’s much more prevalent. It goes like this:
- Company has agenda
- Company generates data
- Company uses data to market
- Data goes through agenda filter
Some companies do this really, really well.

spotify ad campaign feature
But when we read that data, we’re not always aware what the company’s agenda is.
But research about the benefits of Silan-Tehini Shakes are very different if published by JAMA or Jamba Juice.
The data isn't always wrong, of course. It just can't be 100% trusted.One of the most coolest companies in this space is Zillow, which has been publishing the Zillow Home Value Index for some 25 years.
It’s innovative, leverages real data, and is widely used by publications, real-estate agents, academics, and even the St Louis Fed. I truly believe it’s accurate. However, Zillow mostly makes money by charging real estate agents and property management companies fees. Those clients nearly all prefer prices to remain high. Again, that’s not to say the data is off. The source does matter though.
Important point on this one: I had initially included the previous comment on Zillow following a conversation with a friend and then left it in. Someone on LinkedIn (thank you, Dmitry), flagged it and only reinforced who glaring this problem is. I’m far from an expert in the housing market and if someone hadn’t actually stopped by and pointed out how wrong it is that Zillow wants prices to be high, we’d all continue to be dumber. So I’m leaving this in because while even though I completely flubbed the research (I know Zillow’s index from a marketing perspective but not from a housing market perspective), the point very much stands. I'm wrong and, as Dmitry rightfully points out, you can't trust anyone.
Jimi Hendrix's Muppets, of course
The Lending Club - a company that wants to loan out money - publishes a report on how many Americans live paycheck to paycheck and need loads. A life insurance company runs a survey published in the New York Times saying that fewer than half of Americans have discussed their end-of-life plans with loved ones (ie, that more people need to buy life insurance).
Tech companies sitting on unique, structured data can provide amazing insights. In what world would we have know that artists were really hurting during the actor union’s strike better than Cameo reporting on a 137% increase in artist accounts reactivated during the strike? The data is amazing. But it all needs to be taken with a grain of salt.
My problem is that we blindly accept this data as truth, especially when it gains credence from being picked up by publications. In the New York Times article I mentioned above, Ethos isn’t even identified as an insurance company!
Impartial insurance study
So we can’t trust data. But at least we can trust Google, right?
Wrong. Oh, sooo wrong.
(Warning: This was the most unsettling one for me).
V. SEO: 1, Google: 0 or The Demise of Search Accuracy
Let’s start this off with Cory Doctrow’s Enshittification principle, which says that all tech platforms are destined to die. Doctrow says that platforms like Facebook or Google follow a clear path:
- Platforms are awesome for their users
- Platforms abuse the platform to be better to their business customers (think advertisers, in Facebook’s case)
- Platforms abuse their business customers to be better for the business.
Google, in case you were wondering, is at stage 3.
This was first made clear to me in this wild article about affiliate marketing, written by a review website called housefresh.com.
I recommend reading the entire thing but the bottom line is that when you search for, say, “best air purifier for pet hair,” the top ten Google results include results from:
- Better Homes & Gardens
- Rolling Stone
- Popular Science
- Forbes
- BuzzFeed
This is true for most products you search for.
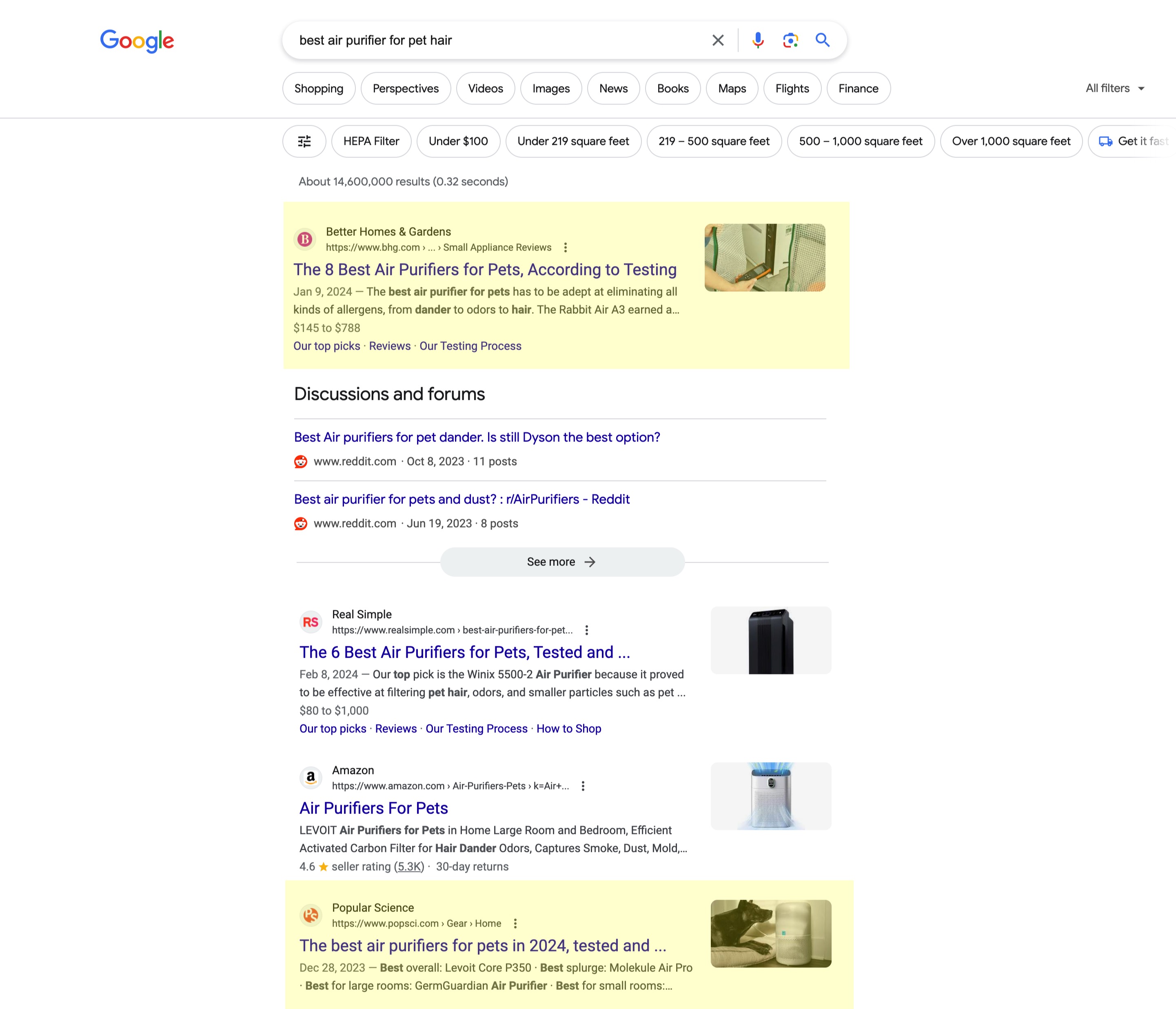
The article details how these companies leverage internal linking, formulaic churned text to placate the SEO gods, stock imagery of products they supposedly tested (with many publications using the same images!) and other nefarious tactics.
The article also points out that, for the most part, these publications have absolutely no clue what they’re talking about:
Better Homes & Gardens recommends the Molekule Air Mini+ as their best option for small rooms. We have no idea how this device made the list considering that Molekule recently filed for bankruptcy, has active class action lawsuits for false advertising, has been recognized by Wirecutter as the worst air purifier they tested, and received the honor of being labeled as “not living up to the hype” by Consumer Reports.
Just to be clear, this is a deliberate strategy spearheaded by PE vultures picking the bones of former media empires. As a more recent HouseFresh article puts it:
Did you know that 19-year-old sports blog Deadspin is now a gambling affiliate site?
That’s right. Just a few weeks ago, Deadspin was sold to a newly formed ghost digital media company that immediately fired all Deadspin’s writers before announcing it would start referring traffic to gambling sites.
Stuff like this happens all the time, but most people don’t follow media news, so they’re completely unaware.
This affiliate strategy is so blatantly obvious and absurd that Nilay Patel, the editor-in-chief of the Verge, has a long running joke where he rips apart Google in a Brother printer review.
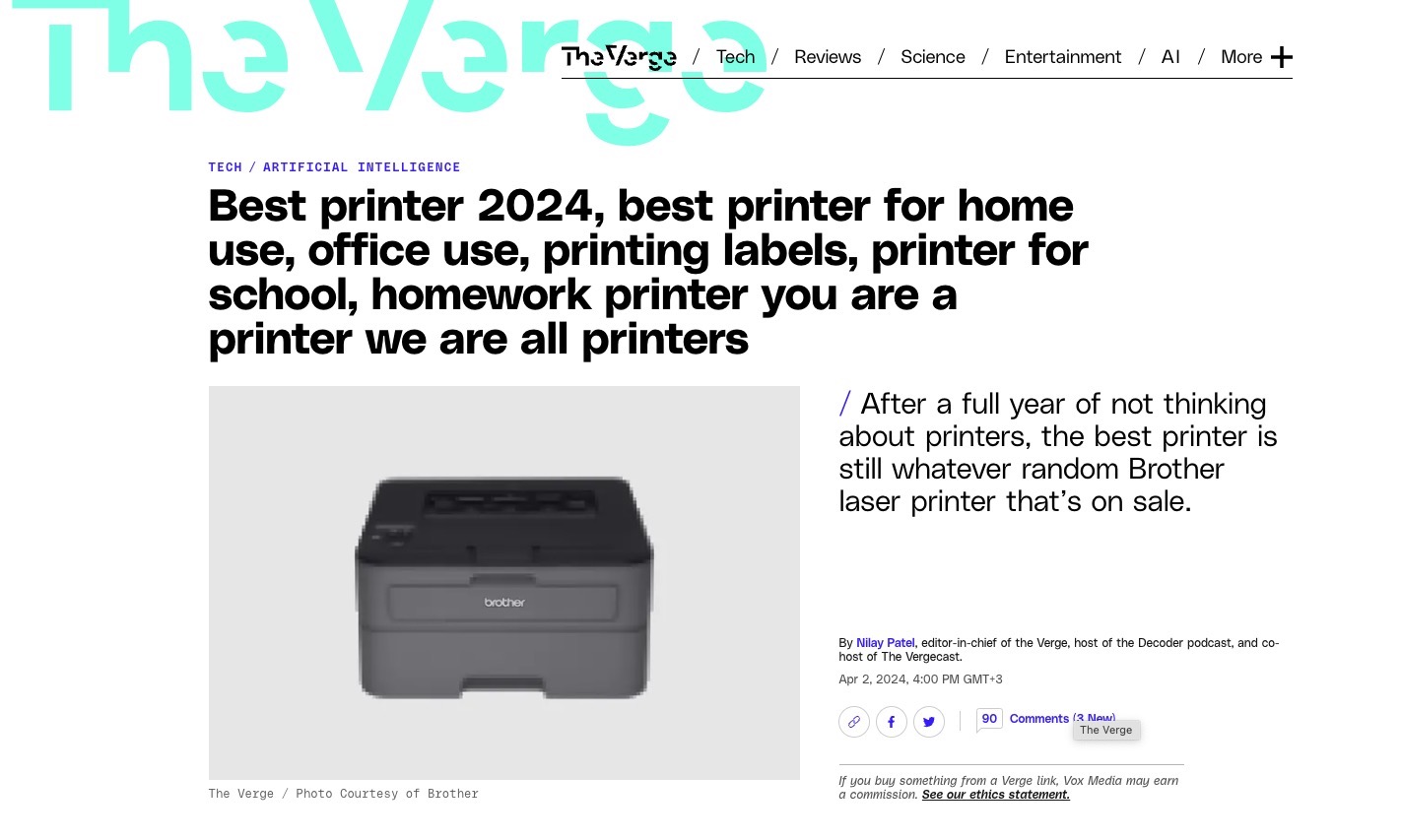
Reporting done right
Here’s the 2024 one:
It’s been over a year since I last told you to just buy a Brother laser printer, and that article has fallen down the list of Google search results because I haven’t spent my time loading it up with fake updates every so often to gain the attention of the Google search robot.
It’s weird because the correct answer to the query “what is the best printer” has not changed, but an entire ecosystem of content farms seems motivated to constantly update articles about printers in response to the incentive structure created by that robot’s obvious preferences.
But the point isn’t that SEO is the worst. The data isn't always wrong, of course. It just can't be 100% trusted. Just because it’s there doesn’t mean someone at Google signed off on it.
I knew this on a sub-concious level but the example above showed me just how wrong I am.
VI. Social? AI? Nope.
Google knows that the articles it taps are gaming the system.
So they rightfully tried to leverage more human-generated content by providing it in results.
It doesn’t work either.
For starters, 5-10% percent of posts are made up by real users when they’re bored.
Fake posts on Reddit got bad enough that the platform created a program in which creators would get paid for good, real posts. And that’s not even talking about bots pushing their own products, content or blog (even though Reddit is - in many cases - famously good at internal policing.
Quora is even worse - any channel that works well for marketers is doomed to be suffused with bots. Google “Quora recommendations for X” about just about anything to see (I’d wager that, for example, every third post in the post about productivity apps is a shill for their own product).
So, coming back to my bleak refrain - SEO game has enshittified Google, prioritizing larger sites, the user-generated content sites themselves are being killed, and media isn’t helpful.
Maybe we can trust AI?
Not the answer either.
As Benn Stancil points out, there are really two ways to think about AI:
- What it can do: Things like write haikus, help code, and create arguments
- What is knows: Things like the corpus of all Shakespeare, laws of physics, and historical legal arguments
ChatGPT and most other AI models rely on LLMs for the first, not the second. AI companies don’t want to take responsibility for getting the answer right.
They can’t. For the most part, most of the answers for part two are based on information not in the public domain, copyrighted material that the LLMs can’t license or based on the same Google results that we know we can’t trust.
That’s exactly why the New York Times is suing OpenAI for scraping them…specifically because AI doesn’t know things and needs publications or books to know them. And it’s exactly why Reddit is licensing data to AI companies.
And, as we said above, it’s hard to put full faith in the fallible, overworked reporters or Reddit.
The most epic examples of all of these combined - SEO, Reddit and AI - was soft-served when Google’s attempts at AI told users to glue cheese to pizza to make it sticky or said that Andrew Johnson, the President of the United States from 1865-1869 “earned 14 degrees from the UW as part of the Classes of 1947, 1965, 1985, 1996, 1998, 2000, 2006, 2007, 2010, 2011, and 2012”.
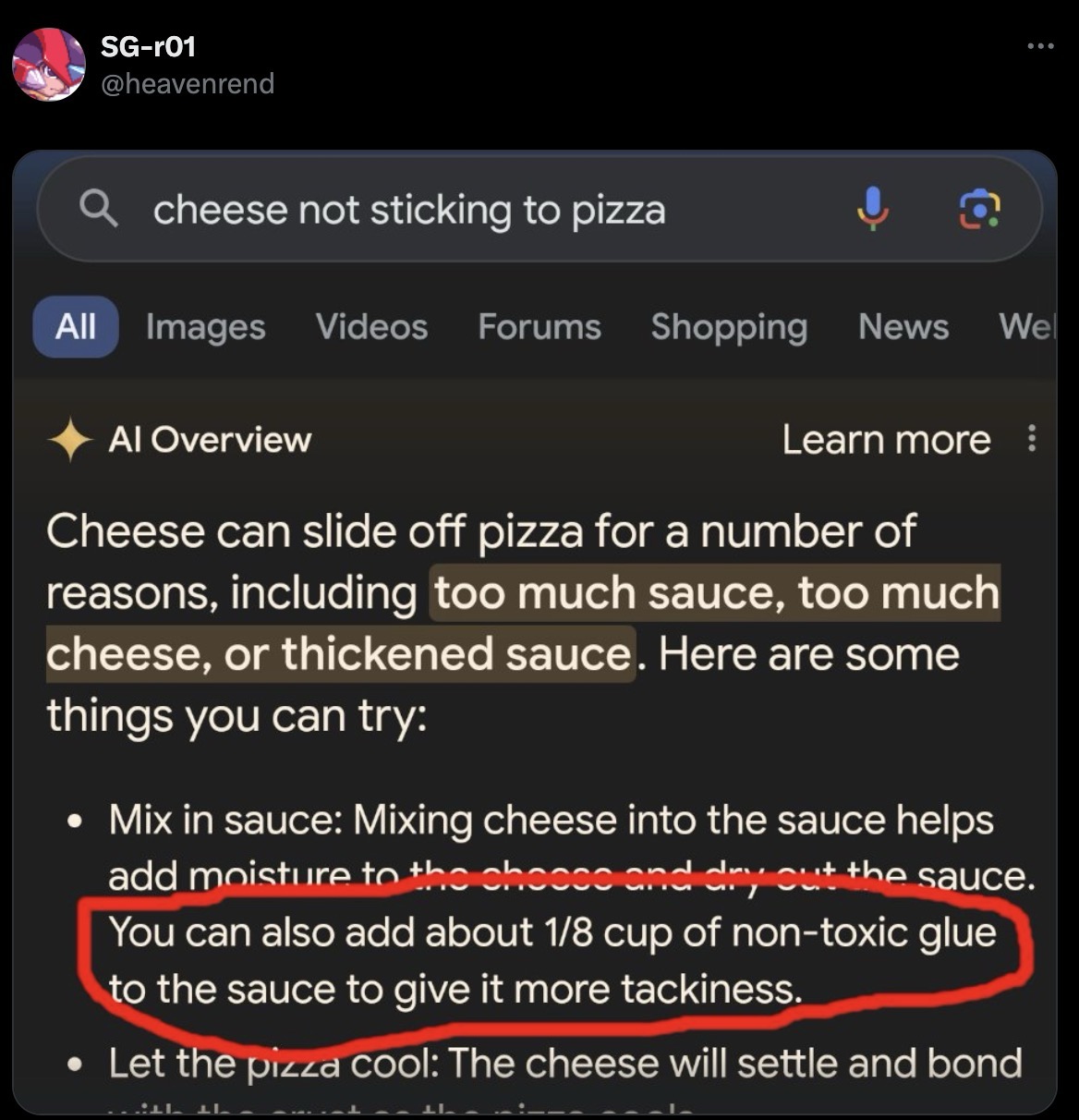
Source: Twitter, Obviously
VII. What About Influencer Marketing?
I started this off by saying that on a rational level, we know that most of these sources can’t be trusted.
Even knowing that… we still read them and things get through. The illusory truth effect shows that even when people know things they are reading are false, they tend to start to believe them. Imagine how much worse that is when we think they might be right.
Part of this might be why influencers or celebrities are more and more popular. For front line reporters, that may actually work - sometimes - but for the lifestyle or tech-bro influencers that are riding Tiktok to the moon, that’s not going to work because:
- Influencers, even the more influential ones, tend to rely on the same crappy information we all have access to
- Influencer incentives aren’t necessarily built around accuracy. In the best case, they chase followers…but are honest enough to not let it take them in the wrong direction.
Again, many influencers - maybe most! - are telling the truth. And some, including folks like Ben Thompson or Lenny Rachitsky, can leverage their status to get access to unique sources. Some are clearly not, like this cryptobro who has made a habit out of lying about having yachts, houses or private drivers…and got busted by someone pointing out that they had stayed at the same…AirBnb.
But it’s rarely this clear. Here’s a fantastic example.
Monday.com’s organic traffic growth is SEO lore, hiring a massive content team to bang out 100 articles in a month and scale to a million clicks in early 2020. It’s the subject of countless influencer posts and case studies (one really good one here). Every one of them reads like it’s true. The influencers have expertise, they have fancy charts and graphs.
But the truth is that they really don’t know.
And here’s another guess about the SEO growth I came across more recently. Monday.com bought the organic growth.
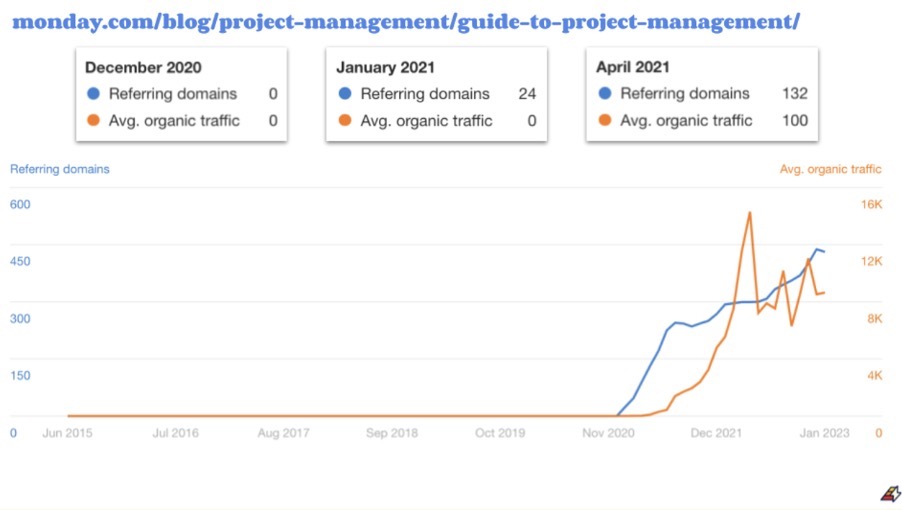
The counter-case study
This analyst figured that based on the graph above - that referring domains kicked in for a pillar piece of content long before organic traffic kicked in - that the true cornerstone of this SEO success was buying backlinks. This isn’t about Monday’s growth. I have no clue who is right...but these are conflicting narratives and only one can be right.
This is just such a good example because the posts:
- Drive value
- Are well researched
- Aren’t necessarily shilling the influencer’s perspective
And still, they can’t both be right.
VIII. Okay, no trust. Got it. So what’s next?
I hope by now it’s clear that we have a ton of information easily accessible but are still left wondering what is or isn’t true. in most of these cases, it’s doesn’t stem from malevolence. But the bottom line is the same regardless - it’s near-impossible to find things we can trust.
Borrowing Trust
Media - when verified and knowledge - is great. I’m also very, very bullish on personal, creator-driven content is what, in my opinion, drives the most credible information, assuming the creator has an endorsement that checks out. A retweet from Bill Gates is not something that is lightly given.
Building personal networks of trust and then having other trustworthy people endorse them is how trust was historically attained and how it will likely continue to be attained.
And I’m not down on AI! I actually think it can help with accuracy rankings, particularly when they use well-annotated, transparent data sets or cross-reference multiple (likely purchased or rented) data sources.
In other words, trustworthy content may start to emerge in a cleaner format. I started off by saying there is more information than ever and that is perhaps the most frustrating part. I have no clue who is right...but these are conflicting narratives and only one can be right. The guy who personally recreated and tested superconductor experiments is a hero but it only takes a few to start casting doubt on the rest.
The implications for building a brand
I obviously can’t ignore the marketing aspects here.
Last year, another executive in our company was talking about a social media post from a competitor. He batted it off by saying “it’s just marketing.”
It’s just marketing.
😱😱😱
People don’t believe marketing claims anymore. They don’t believe case studies and they don’t believe website claims.
They shouldn’t. We’ve killed our credibility with shadow-testing of nonexistent products, slideware that only exists in a pitch deck, and meh tools that don’t work.
This is an opportunity for the right brands.
Building trust is a monumental challenge, which means that most companies ignore it. But it can be done, just not overnight. There’s no secret recipe, just things that prove bonafides. Things like:
- Product led growth that let users actually kick product tires and try it out themselves
- Word of mouth growth, in which trusted friends or colleagues certify authenticity
- Video testimonials - ideally authentically filmed ones - with well-known companies or leaders in the industry.
- Education that goes incredibly deep and oozes competence, like Superhuman’s deepdive into finding product market fit
- Ongoing content efforts that leverage transparent data or researchers who have proven themselves. Marketers may not trust what Google says…but they tend to trust what Google’s search liaison, John Mueller, says, at least a little more.
Fear not, I’ll dive more into these ideas in another article since this is getting way, way too long.
For now, I’ll just leave you with the fact that we have more information available than ever before. But we don’t know anything.
Remember this when consuming content. Take everything with a grain of salt, questioning what we read, and validating sources. And when we create content, we need to remember that these days, content is cheap.”
Trust is in short supply.Let's make a deal. Drop your email and I'll let you know when I post new insights.